
The output of many complex industrial simulations is extremely complicated and depends on a large number of input parameters. Whilst these simulations have had huge impact since they are substantially faster than real-life experimentation, they still take hours or even days to produce output for a single configuration of their input parameters. This makes them orders-of-magnitude too slow to be used for many applications, for example, Electric-Vehicle (EV) battery simulations are currently too slow for use in battery management systems.
For complex simulations to be more widely applicable as practical solutions where near real-time calculations are needed, there is a strong need for AI surrogates which learn how to reproduce simulation output in fractions of the time taken by the original simulation.
In order to build an effective AI surrogate of a simulation there are two key ingredients. First, it is essential to provide your machine-learning model with a training set that contains all the essential features of your simulation, without this you cannot hope for the resulting AI surrogate to be a reliable representation of the true simulation. Second, you need to correctly characterize the inherent imperfections associated with all machine-learning models, without this your AI surrogate will return output for any given configuration of input-variables, but this output will often be quite wrong (i.e. different to the true value it aims to emulate).
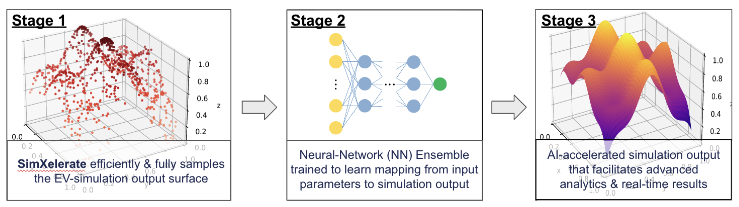
SimXelerate uses the PolyChord full-coverage sampler to generate its training set, this guarantees a complete and robust training set. Then this training set is passed through a bespoke machine-learning process that delivers the likely correct prediction of the original simulation’s input given the passed input parameter configuration, as well as its uncertainty. This guarantees that your answer is both accurate and complete, delivering a drastically superior AI emulator.
Customer Case Study - AVL EV-battery simulations
For AVL Advanced Simulation Technologies, we validated how PolyChord’s full-coverage sampling of their EV battery simulation, in combination with our cutting-edge machine learning techniques, delivered a far superior AI emulator of their original simulation. In our initial work for them, we considered a simulation with 39 parameters, but PolyChord will work effectively for 100s of parameters.
The SimXelerate AI emulator delivered non-biased, i.e. representative of the truth, simulation outputs in under a second, rather than minutes as with the original simulation. With this AI emulator, a complex design-space query that took 11 weeks with the original simulation was done in less than an hour using SimXelerate. The animation on the right shows SimXelerate producing EV-battery simulation output in almost real time as a user adjusts the settings of the input parameters on the control panel to the right. Each user adjustment would've taken the original simulation over a minute to recompute and update the output values depicted by the heights of the bars on the left.
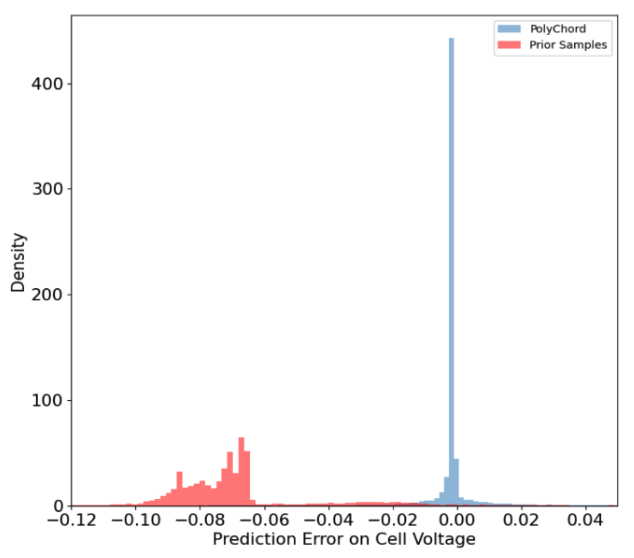
The plot to the left shows the density of model predictions that have a particular prediction error (established using a test data set, previously unseen by the network). The more tightly centred around a zero prediction error, the better the model. The PolyChord-sampled training set (blue) substantially outperforms a standard-sampling approach (red) as it is tightly centred around a 0% prediction error, whereas the red distribution is concentrated between a prediction error of 6% and 10%. Importantly, these differences are most marked around the peaks of the simulation output (the metric being maximised in an optimisation), where information is completely missing from the standard-sampled training set.